
Quickly get actionable metadata insights about ALL of your data.
nLite by XtremeData generates real-time metadata that provides context and details about all of your data. As you understand your data better, it becomes easier to work with. Such metadata makes your data more discoverable, accessible, and usable.
Improve the quality of your data.
nLite helps validate data and ensure its quality by documenting data attributes, changes made to data sets, and any errors found.
Reduce the time & cost to onboard, prepare, and analyze data.
Using nLite saves you time and money by reducing data redundancy, minimizing storage costs, and optimizing data usage.
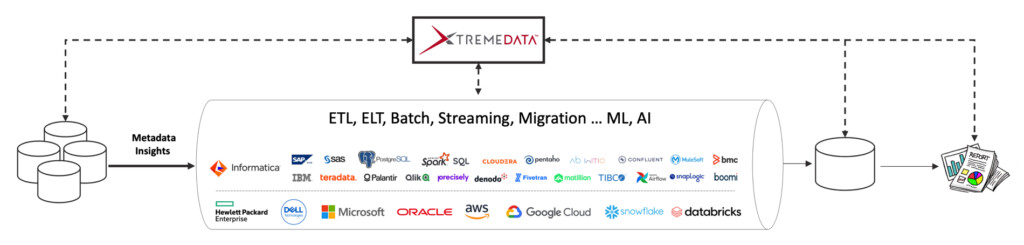
Enhance your AI, ML, analytics, privacy, and governance.
By detecting issues early, nLite enables proactive DataOps, reduces hallucinations in your AI, improves data governance, , accelerates data onboarding, and ensures trustworthy, actionable intelligence — at scale, on-prem, in the cloud, or at the edge.
Use GUI or 230+ APIs to generate & analyze metadata.
Engage in interactive or batch data discovery from full data sets in files and databases with comprehensive metadata analysis via an easy-to-use, no-code GUI or APIs.
No agents, no schema dependencies, no coding, no copying, no moving, no sampling.
nLite is a turnkey, auto-scalable solution that does NOT copy, move, or sample your data. It integrates with any ecosystem via JDBC/ODBC, quickly scans all of your data in files or databases, and generates metadata you can use in data governance, AI, analytics, and more.
Most tools generate metadata by sampling source data. Such metadata does not truly reflect the source data and is inadequate for building and maintaining high-quality AI/Analytics data. It leads to incomplete, incorrect, and misleading insights that result in iterative lifecycles, slow data onboarding, and higher DevOps and DataOps costs.
nLite overcomes this industry-wide problem by using full fidelity metadata processing technology. With deep data discovery for full data sets and robust metadata insights, the data governance, engineering, and analytics tasks that take hours (or even days) to complete can be performed in seconds.
 Scan data in files and databases in public clouds or on-premises.
Scan data in files and databases in public clouds or on-premises.
nLite works no matter where your data resides:
- Public clouds (AWS, Azure, Google Cloud, etc.)
- On-premises
- Files (CSV, text, Parquet, etc.)
- Databases (Postgres, Spark, SQL Server, Oracle, Snowflake, etc.)
- At rest or in motion
100x faster & lower cost than SQL.
nLite takes 50x less compute than custom queries in Spark and SQL solutions, enabling full fidelity metadata for millions of data sets at rest and in motion in exabyte-scale data lakes.
In-depth data discovery generates comprehensive metadata.
nLite performs several important data tasks. The first is Data Discovery, when it generates metadata by:
- Profiling: column-level metadata comprising 34 summary attributes, 8k data value patterns, 15 rank values, 16k most common values, and 16k outlier values for each column.
- Schema Inferencing: SQL schema generation from data files with precise data types, nullable types, and composition of data values.
- Rules: determines the validity of data values of a source data set by evaluating boolean expressions for one or more columns, either custom or predefined, on its data values.
- References: finds the accuracy of column references of a referencing (FK) source data set with respect to a referenced (PK) data set.
- Lookups: evaluates the accuracy of a source data set by looking up its column values in a master or dictionary data set.
- Domain Class: identifies domain classes in source data values that conform to specified data values and pattern expressions, either custom or predefined – a great way to identify sensitive data.
Use nLite to analyze metadata.
The second key task nLite performs is Metadata Analysis:
- Single Column Analysis: derives data insights at the level of a single column of a source data set across several attributes of data values.
- Search: searches across all columns of a source data set for columns storing special characters (like CR, LF, ESC, etc.), data value patterns, regular expressions, key and unique columns, and more.
- Multi-Column Analysis: examines data attributes across multiple columns of a source data set from its profile metadata.
- Span Analysis: performs column property analysis across multiple profile metadata sets for a column identified by its name or position.
- Drift Analysis: compares columns of selected profile metadata sets of similar source data or silos, by name or position, on a column property to identify drift in schema, cardinality, statistics, and data values.
- Constraints Type Metadata: examines results of constraint type metadata for rules, references, lookup, and domain class.
Quantify the quality of your data.
The third crucial task nLite performs is improving Data Quality. With nLite, you can learn:
- Completeness: how complete are column data values, in terms of real-world values vs nulls, empty or blank strings, and zeros.
- Conformance: the degree of type conformance of column data values vis-à-vis their assigned data type.
- Consistency: the uniformity of data format and representation of data values of a column for its type.
- Uniqueness: the uniqueness of column data values and their distribution with respect to duplicates.
- Validity: data value correctness with respect to business rules, range conformance, semantics, etc., using rules metadata.
- Accuracy: how accurate are data values vis-à-vis master or certified data through reference and lookup metadata evaluation.
- Timeliness: how relevant are metrics or metadata with respect to source data in terms of the temporal age of data.

How orgs use nLite’s metadata…
Current subscribers of nLite use it to complete a myriad of data tasks, including:
- Monitor data lakes for data quality, privacy, and more
- Monitor ETL and ELT pipelines to detect anomalies before data is ingested into data warehouses
- Monitor AI/ML pipelines for data and schema drift
- Reduce data duplication and associated processing
- Generate high-quality test data
- Accelerate data conversions & migrations
- Consolidate data across multiple databases
- Data regulations compliance and reporting by providing detailed records of data owners, access rights, and data retention policies